自2021年7月20日南京禄口国际机场例行检测到新冠阳性病例以来,疫情很快通过航空跨省传播,又正值暑假旅游旺季,疫情在湖南的张家界、常德等地再次聚集性暴发,呈现多点扩散外溢态势。此次疫情病毒毒株为德尔塔毒株,其传播力更强,潜伏期更短,给疫情防控带来很大的挑战。
西安交大数学与生命科学研究中心有着疫情传播分析的良好研究基础和优势,曾成功分析并预测了“非典”和新冠病毒的流行趋势。面对近期疫情的再次蔓延,中心始终坚持“四个面向”,以服务国家重大需求和人民生命健康为己任,迅速集结团队科研骨干,全力开展疫情防控科研攻关。数学与生命科学研究中心、人工智能与数字经济广东省实验室(琶洲实验室) 、陕西师大数学与统计学院联合西安市疾控中心和南京医科大学公共卫生学院,结合国际上德尔塔毒株的传播力,建立符合现有防控措施的数学模型,并拟合多源疫情数据来预测此次疫情的发展趋势和规模,以此评估此次疫情的传播风险,为新冠疫情的精准防控提供理论支撑。
原文链接:http://xiammt.xjtu.edu.cn/info/1004/3021.htm
南京关联的新冠疫情分析、预测与决策建议
人工智能与数字经济广东省实验室(琶洲实验室)、西安交大数学与生命科学研究中心、陕西师大数学与统计学院、西安市疾控中心、南京医科大学公共卫生学院
自2021年7月20日南京禄口国际机场新冠疫情集聚性暴发以来,疫情很快通过航空跨省传播,成为输入性疫情引发国内传播的新模式。由于正值暑假旅游旺季,疫情在湖南的张家界、常德等地再次聚集性暴发,呈现多点扩散外溢态势。此次疫情病毒毒株为德尔塔毒株,其传播力更强,潜伏期更短,给防控带来很大的挑战。为了评估此次疫情的传播风险、预测发展趋势和规模,我们结合国际上德尔塔毒株的传播力并发展符合此次疫情防控模式以及疫情数据的数学模型进行分析、预测并为精准防控提供决策依据。
一、 基于统计分析和英国数据对德尔塔毒株的基本再生数的估计
德尔塔毒株的传染能力极强,基于英国的疫情数据和病毒测序数据,我们研究得到:当假设代际间隔5天(标准差3天),德尔塔毒株的基本再生数比阿尔法病毒高49% (CI: 45-52%)。事实上,Alpha的传播能力已经有一些相关研究,其中Science文章得到Alpha的再生数是原始新冠毒株的1.4-1.9倍。 若取Alpha的再生数是原始新冠毒株的1.5倍,原始毒株的再生数是2.5,则得到Delta的再生数是2.5*1.5*1.49=5.59; 若原始毒株的再生数是3.5,则得到Delta的再生数是3.5*1.5*1.49=7.82。 因而德尔塔毒株的基本再生数为5-10。
二、 基于确定型模型和近期全国数据的疫情发展趋势分析
2.1数据与模型 依据此次疫情的实际情况,构建了如下的传播流程图(如图1所示),融合新增确诊病例数、新增无症状病例数、新增无症状转确诊病例数以及各地密接隔离人数等四列数据,通过随机模型、确定性模型以及统计模型进行模型参数估计和有效再生数估计,预测此次疫情的发展趋势,并确定本轮疫情的感染规模和停时。我们关注到:由于几乎所有的病例都直接或间接的与南京禄口机场关联,故目前的模型构建没有考虑地域上的分布,所用的数据也是此轮疫情的总数据。
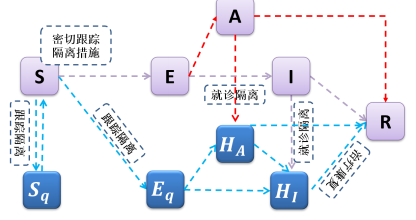
图1:密切跟踪隔离新冠传播模型流程图,其中HA表示报告的无症状感染者,HI表示报告的确诊病例。Sq ,Eq表示隔离的密接人数。其它变量为通常熟知的模型变量。
2.2基准预测,即维持国内7月29日之前的防控力度。通过同时拟合多源数据 (每日确诊病例数、无症状感染数、隔离人数、新增无症状转确诊病例数等),估计了系统的未知参数,预测了疫情在近期的走势。当维持国内7月29日之前的防控力度,如图2-3所示,此次疫情的拐点可能出现在8月1日(95%CI: [7月31日,8月2日],而有效再生数将在7月31日(95%CI:7月30日至8月1日)之后维持在1以下。据模型预测:截至到8月20日,累计新增确诊925人(95%CI:[733,1364]),累计新增无症状感染者109人(95%CI:[77,151])。
2.3防控加强,即从7月29日开始加强相关防控措施。不妨假设人均日接触数c开始指数递减。据模型预测:截至到8月20日,累计新增确诊633人(95%CI:[523,805]),累计新增无症状感染者80人(95%CI:[58,104]),如图4所示。当考虑更多防控措施的进一步加强,比如个体防护、检测率等的提升,疫情规模有可能进一步下降。
2.4疫情外溢,即间歇性出现新的聚集性暴发点。考虑到疫情的外溢,各地若不能及时的发现确诊病例,这些隐藏的病例(未及时发现或无症状感染者)又在各地流动,致使高危易感人群数量骤增。为了测试和预测其影响,不妨假设高危易感人群数量日增3万人。据模型预测:截至到8月20日,累计新增确诊1235人(95%CI:[858,2660]),累计新增无症状感染者142人(95%CI:[89,284]),如图5所示。
三、 数据与模型分析及疫情防控决策的建议与思考
3.1疫情外溢的挑战性 此轮突发疫情溢出速度快,假期人口流动频繁,导致易感人群规模不断显著和疫情呈现多点聚集性暴发,密切跟踪隔离策略实施难度大。数据分析和模型模拟显示:多增加一个集聚性爆发点,疫情规模有可能显著增加。特别的,累计确诊病例增加约33%,但是若及时发现潜在的感染者,累计确诊病例只增加约4.5%。以7月30日以前的疫情数据确定模型基准参数,得到:
Ø 若从7月30日开始,每日增加30000易感者,截至8月20日,累计确诊病例数1235人 (95%CI:[859,2665]),累计无症状感染者142人 (95%CI:[89,284])。累计确诊病例增加了33.51%,累计无症状感染者增加了30.28%。
Ø 若在7月30日同时引进3个潜伏期感染者且日增30000易感者,截至8月20日,累计确诊病例数1240 人(95%CI:[863,2672]),累计无症状感染者143人(95%CI:[89,285])。累计确诊病例增加了34.05%,累计无症状增加了31.19%。
Ø 上述两种情况下,若易感者只日增3000人,或3个潜伏期感染者且日增3000易感者, 则累计确诊病例数只增加了4.76% 或5.08%, 累计无症状感染者只增加了4.59%,或4.59%。
3.2精准防控的重要性 模型模拟显示,即使输入3例无症状感染者,在每日新增3000易感者规模的情况下,局部集聚性疫情基本在发现输入病例后,不会有太大的增长(如张家界疫情)。由此可见,疫情防控关键还是在于早发现、早隔离感染者、防治易感人群规模的扩大,实现精准防控。以7月30日以前的疫情数据确定模型基准参数,考虑两种控制措施,一是密切跟踪隔离(一种精准化的筛查策略,即 越大,精准筛查力度越强);二是,全民筛查策略(即
越大,精准筛查力度越强);二是,全民筛查策略(即 越大表示筛查强度越高,从而隔离速度越快)。不同精准筛查强度、全民筛查对疫情防控影响的敏感性分析见表1。基于此,得到的结论是:精准筛查(密切跟踪隔离)可以有效控制疫情的蔓延。而当精准筛查强度较弱时,全民筛查亦可以很大程度降低感染规模,但是精准筛查足够的情况下,全民筛查对疫情控制作用有限。
越大表示筛查强度越高,从而隔离速度越快)。不同精准筛查强度、全民筛查对疫情防控影响的敏感性分析见表1。基于此,得到的结论是:精准筛查(密切跟踪隔离)可以有效控制疫情的蔓延。而当精准筛查强度较弱时,全民筛查亦可以很大程度降低感染规模,但是精准筛查足够的情况下,全民筛查对疫情控制作用有限。
3.3防控决策建议与思考 1)及时跟踪、筛查,最大限度降低由新增集聚性暴发点导致的易感人数增加规模;2)加大疑似病例或隔离人群的筛查力度,及时发现确诊病例特别是无症状感染者;3)针对此次疫情,如果能对潜在溢出的感染者、高危密切接触者进行精准识别,积极开展流行病学调查和核酸检测筛查,是能够做到尽快清零的。
表1. 精准防控与全面筛查的敏感性分析
|

|
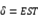
|
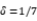
|
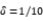
|
|
无症状规模 |
确诊规模 |
无症状 |
确诊规模规模 |
无症状规模 |
确诊规模 |
无症状规模 |
确诊规模 |
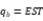
|
88 (56,125) |
676 (514,1037) |
109 (77,151) |
925 (733,1364) |
107 (66,155) |
1036 (822,1439) |
103 (62,157) |
1056 (821,1437) |
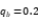
|
123 (72,235) |
1075 (695,2387) |
176 (102,319) |
1648 (1102,3105) |
175 (90,319) |
1912 (1330,3254) |
169 (84,310) |
1951 (1398,3168) |
|
与基准估计(标红)比较的百分比 |
|
-19.27% |
-26.92% |
0 |
0 |
-1.8% |
12% |
-5.5% |
14.16% |
|
12.84% |
16.22% |
61.47% |
78.16% |
60.55% |
106.7% |
55.05% |
110.92% |
注:‘EST’ 表示估计值。
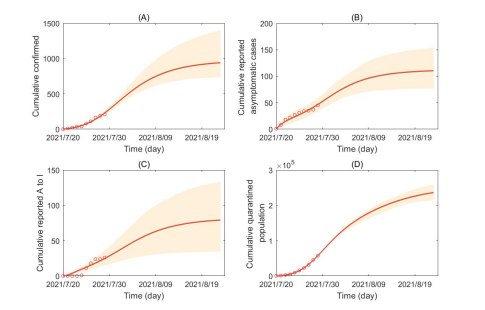
图2:基于确定性模型的数据拟合结果及预测.其中红色圆圈表示实际数据,深红色曲线为最优拟合结果,阴影区域为95%置信区间。

图3:有效再生数,阴影区域为95%置信区间。
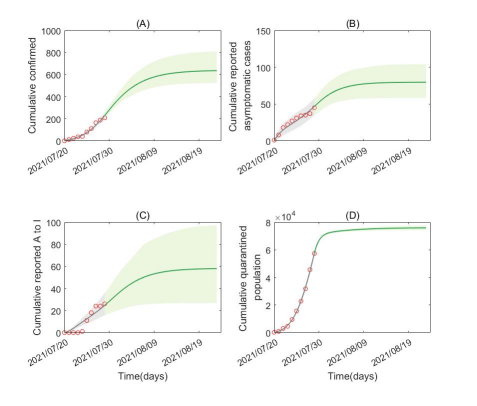
图4:防控措施进一步加强的情形下,疫情发展趋势的预测。这里假设从数据的最后一个点(七月29日)开始控制措施加强,即接触率c开始指数递减。
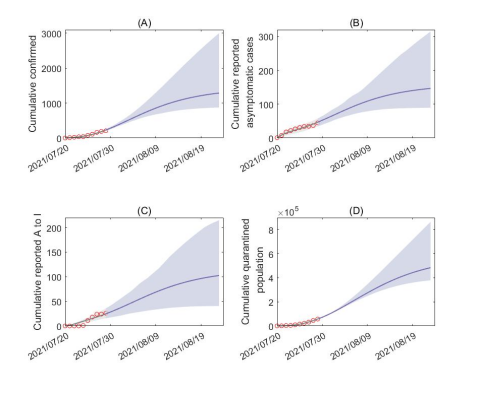
图5:易感人群规模不断扩大情形下,疫情发展趋势预测。这里假设从数据的最后一天(7月29日)开始,每天增加30,000的易感人群规模。


